 按钮,开启“图表联动”功能即可使用。视图之间可联动显示的要求是:来自同一数据表。联动方式可支持1对1和1对多。
按钮,开启“图表联动”功能即可使用。视图之间可联动显示的要求是:来自同一数据表。联动方式可支持1对1和1对多。
执行分析 |
创建地图和图表后,通过查看单一的地图或图表,许多模式和关系并不是很清晰,接下来,您可以通过数据洞察提供的视图联动功能,发现空间数据和属性数据之间的关联,通过空间分析功能,进一步提取和挖掘空间信息价值,或通过连接数据科学服务,进行高级的自定义扩展分析。
数据洞察中提供的视图联动功能,用于发现空间数据和属性数据之间的关联。在上方导航栏中点击按钮,开启“图表联动”功能即可使用。视图之间可联动显示的要求是:来自同一数据表。联动方式可支持1对1和1对多。
具体操作为:在地图或图表中任意选择数据,与被选中数据有关联的图表将高亮显示。如下图所示,在右上柱状图中点击“最热七天气温”为28到35度的两个柱条,则温度属于该范围的站点在左上地图上突出显示,同时在左下视图中,气象站属于哪个省份也以醒目的颜色显示。

选择任一联动视图中的![]() 图标,可清除高亮,进行联动数据的重新选择。
图标,可清除高亮,进行联动数据的重新选择。
空间分析是基于地理对象位置和形态的空间数据的分析技术,其目的在于提取和挖掘空间信息价值。数据洞察提供了标准空间分析以及分布式分析两种分析方式。标准分析具体包括:缓冲区分析、提取等值线、提取等值面、叠加分析、泰森多边形和 IDW 插值分析等。分布式分析具体包括:点聚合、属性汇总、密度分析、轨迹重建、叠加分析、缓冲区分析和区域格网构建等。 在数据洞察中,空间分析的结果是一个新的数据表,同样支持创建图表和再次空间分析,通过空间分析得到的数据表,在列表中会采用 符号标识。
符号标识。
在进行空间分析前,需要 iPortal 管理员在管理页面中添加 iServer 托管服务器和配置关系型存储。
标准分析和分布式分析所支持的具体数据格式如下表所示:
| 数据类型 | 标准空间分析 | 分布式空间分析 |
| Excel 数据 |
√ |
√ |
| CSV 数据 |
√ |
√ |
| GeoJSON 数据 |
√ |
√ |
| JSON 数据 |
√ |
|
| SHP 数据 |
√ |
|
| 注册的 HDFS 数据 |
|
√ |
| 注册的 HBase 数据 |
|
√ |
标准空间分析支持 Excel、CSV、GeoJSON、JSON、SHP 等格式的数据,数据洞察提供了以下两种标准空间分析方式:
数据洞察首选使用客户端空间分析,您可以手动更改空间分析方式:选择导航栏中的 设置按钮,在弹出的设置选项卡中,选择“分析设置”,在“首选分析方式”中勾选需要的分析方式,点击“确定”按钮即可。
设置按钮,在弹出的设置选项卡中,选择“分析设置”,在“首选分析方式”中勾选需要的分析方式,点击“确定”按钮即可。
缓冲区分析是对一组地图要素(点、线或面)按设定的距离条件,围绕这组要素形成具有一定范围的多边形实体,从而实现数据在二维空间扩展的一种分析方法。数据洞察中的缓冲区分析如下图所示,创建好地图视图后,选择右侧工具栏中的“空间分析”,选择“缓冲区”,点击“分析图层”,可切换用于创建缓冲区的要素,默认为第一个图层。

其中 “缓冲半径”参数,可设置缓冲区的范围,单位为千米;保留原对象字段属性,设置后生成的缓冲区将包含点(线、或面)对象的属性信息;合并缓冲区,设置后对相交缓冲区进行合并。
等值线是地图上表示表面的常用方法之一,其通过将所有数值相等的相邻点连接,而形成光滑曲线。常用的等值线使用场景有:等高线、等深线、等温线、等压线、等降水量线等等。

其中具体参数为:
等值面是由相邻的等值线封闭组成的面,通过等值面的变化可以很直观的表示出相邻等值线之间的变化,诸如高程、温度、降水、污染或大气压力等,可以非常直观和有效的表达数据分布。数据洞察中的提取等值面的参数与提取等值线相同,区别是分析结果是面要素,且分析结果属性字段中包含最小值和最大值,如下图所示:

叠加分析是通过对空间数据的加工或分析,提取需要的新空间几何信息的一种分析方法。比如需要了解某一个行政区内的土壤分布情况,就可以根据全国的土地利用图和行政区规划图这两个数据集进行叠加分析,得到需要的结果。叠加分析广泛应用于资源管理、城市建设评估、国土管理、农林牧业、统计等领域。数据洞察提供的叠加分析,如下图所示,通过叠加分析,计算出地铁周边1公里范围内有哪些小区。数据洞察中叠加分析支持的还包括:裁剪、擦除、同一、相交、合并、更新等多种运算方式。

泰森多边形可用于定性分析、统计分析和邻近分析等。例如可以用离散点的性质来描述泰森多边形区域的性质,可以用离散点的数据来计算泰森多边形区域的数据,并且可以通过泰森多边形直接得出判断一个离散点与其它哪些离散点相邻。数据洞察中支持泰森多边形分析,分析数据的类型必须为点,分析结果为面数据,每个面中有且仅有一个点数据,面对象的属性与点对象相同,并且可指定裁剪范围,具体操作为当前视图增加一个面图层,然后设置裁剪图层名称,生成的结果仅包含在面范围内,如下图所示:

插值分析是通过采样点的测量值,使用适当的数学模型对区域所有位置进行预测,形成测量值表面的一种空间分析方法,数据洞察支持 IDW 插值分析,可通过对各个待处理像元邻域中的样本数据点取平均值来估计像元值,并且可指定裁剪范围,具体操作为:在当前视图增加一个面图层,然后设置裁剪区域为该面图层,生成的结果仅包含在面范围内,如下图所示:

数据洞察支持对配置了关系型存储的 CSV、Excel、GeoJSON 格式数据、注册的用户自管理的 HDFS 数据和 HBase 数据进行分布式空间分析。使用分布式分析功能,需要管理员配置分布式分析服务器,具体配置过程请参见:分析服务器配置。
配置完分布式分析服务器后,选择导航栏中的设置按钮,在弹出的设置选项卡中,选择“分析设置”,在“分布式分析服务器”一栏中选择配置好的服务器地址,点击“确定”按钮即可。
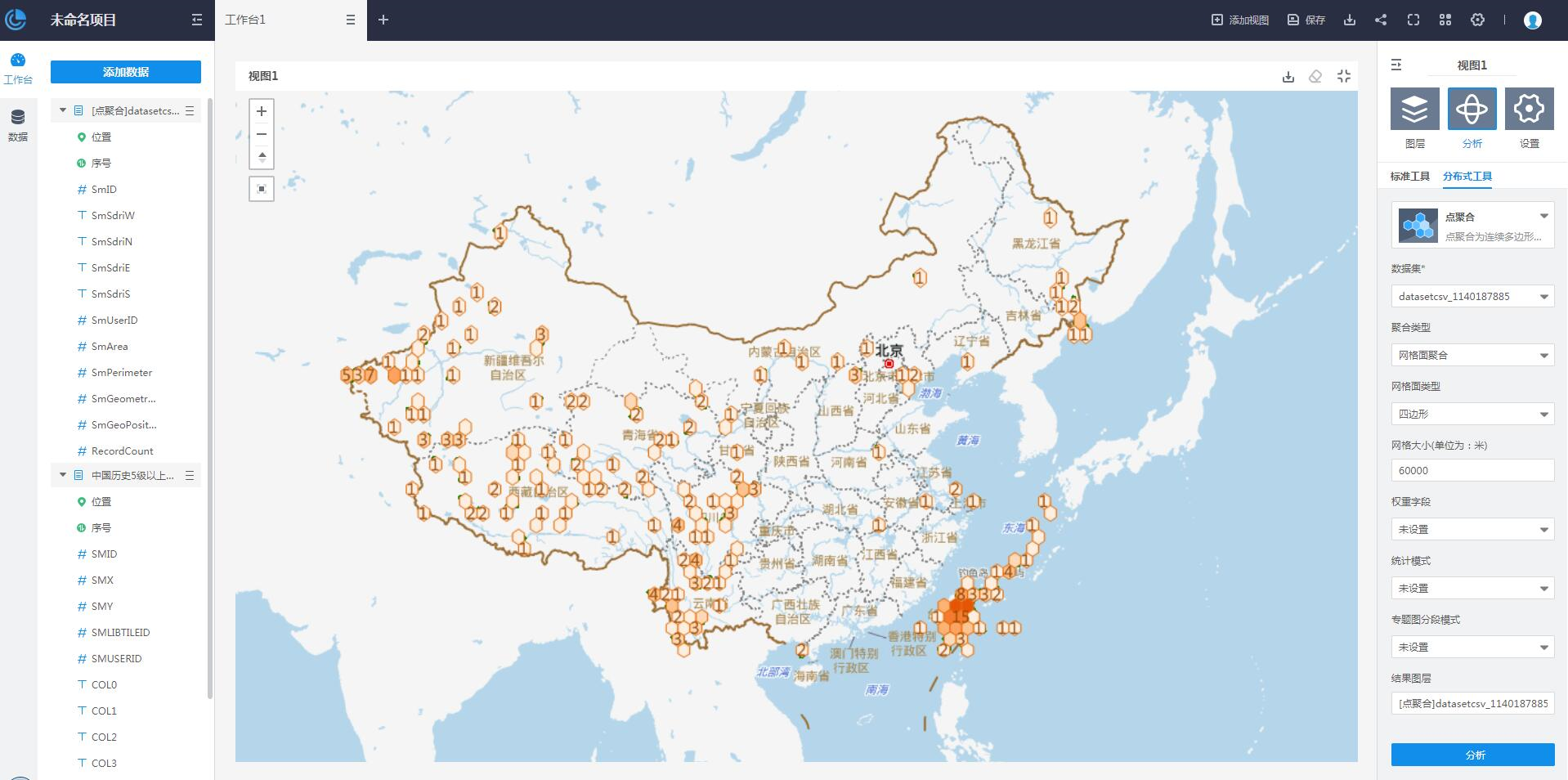
点聚合分析是一种针对点数据集制作聚合图的空间分析方法。通过网格面或多边形对地图点要素进行划分,然后计算每个面对象内点要素的数量,并作为面对象的统计值,也可以引入点的权重信息,考虑面对象内点的加权值作为面对象的统计值;最后基于面对象的统计值,按照统计值大小排序的结果,通过色带对面对象进行色彩填充。 数据洞察支持网格面聚合和多边形聚合两种点聚合分析类型。
在右侧工具栏中选择“分析->分布式工具->点聚合“,开始点聚合分析作业。
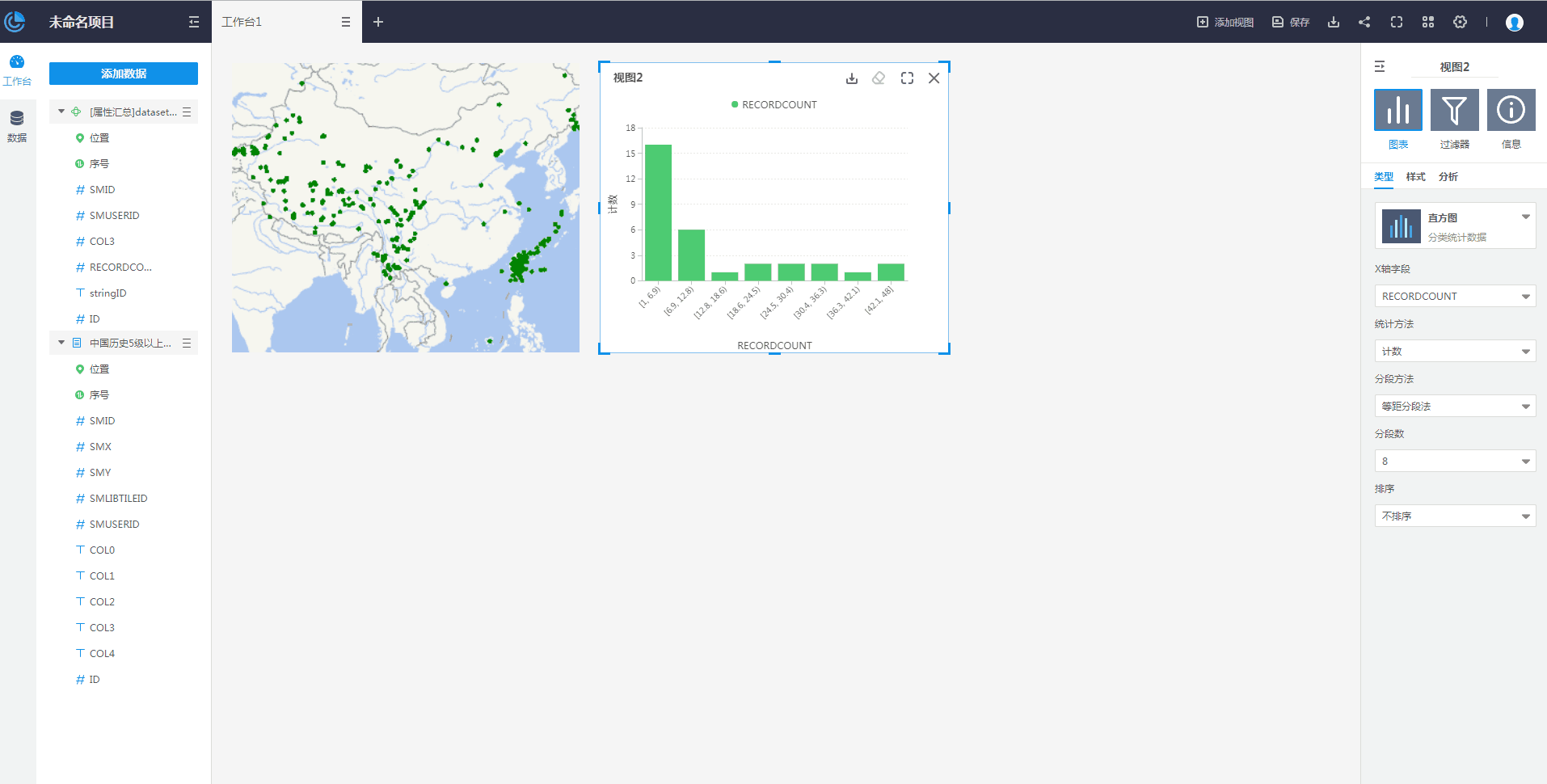
属性汇总是对输入的数据集中所选择的属性进行汇总统计的分析方法,通过对输入的数据集设定分组字段、属性字段以及对属性字段需进行的统计模式,从而得到汇总统计的结果。属性汇总的结果可由直方图等统计图表的形式进行展示。
属性汇总分析的参数设置如下:
密度分析,用于计算点、线要素测量值在指定邻域范围内的单位密度。简单来说,它能直观的反映出离散测量值在连续区域内的分布情况。数据洞察目前支持简单点密度分析和核密度分析:

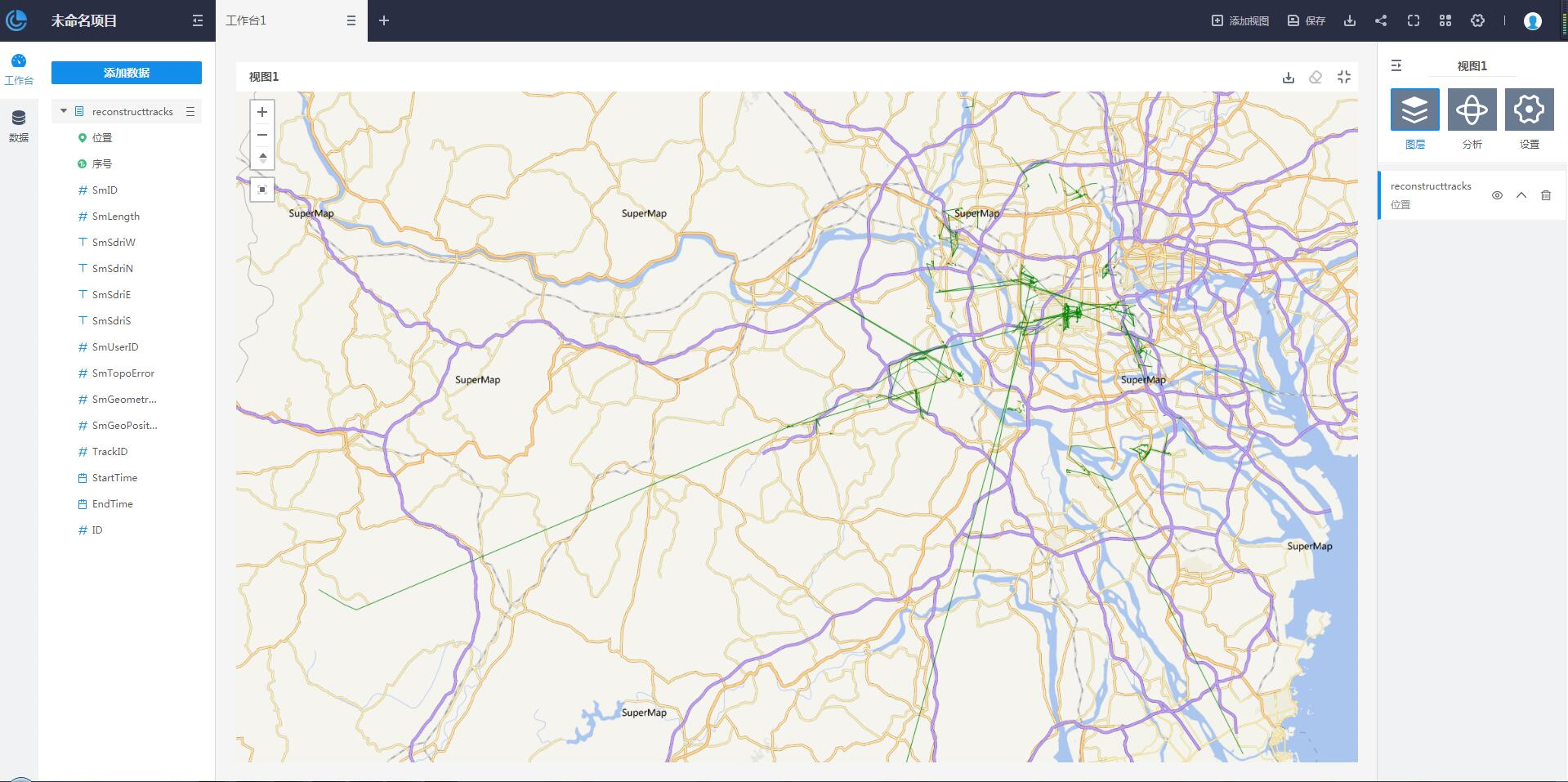
轨迹重建功能可以通过不同时间下物体所处的不同位置,来重建轨迹线或轨迹面,描述出该物体的运动轨迹,同时可对指定属性进行统计。例如车辆在行驶时会每隔一段时间将其所处的位置通过 GPS 上传到服务器中,这样在服务器中就会存储该辆车的 GPS 数据,而通过该数据可以使用轨迹重建功能来构造出车辆在一段时间内的运动轨迹,更直观的看出车辆的运行状态。要进行轨迹重建分析,数据集中必须包含时间属性字段。
分布式叠加分析功能可以对空间大数据进行叠加分析,通过图层间的裁剪,擦除,合并,相交等空间几何运算方式提取出所需的空间信息。分布式叠加分析目前支持的数据类型包括:配置了关系型存储的 CSV、Excel、GeoJSON 格式数据以及用户注册的 HBase 数据。

缓冲区分析是围绕空间对象,使用与空间对象的距离值(称为缓冲半径)作为半径,生成该对象的缓冲区域的过程,其中缓冲半径可以是固定数值也可以是空间对象各自的属性值。缓冲区也可以理解为空间对象的影响或服务范围。

区域格网构建是根据输入的区域面数据,按照给定的格网的宽和高,生成可以完全覆盖区域面的格网面数据集,其中生成的每一个格网必定与区域面是相交的关系。构建格网面后,支持传入点数据来进行格网内部的统计,将每个格网内的点的统计值写到格网面的属性中。

空间分析结果会以数据表的形式自动存储到“我的数据”模块,您可以将分析结果共享给其他 iPortal 用户或应用,具体请参见:共享分析结果。
数据科学是指通过各种科学方法、算法和过程从大量数据中提取价值。借助数据科学能力,数据洞察 WebApp 可以实现用户高级的自定义扩展分析及分析结果可视化。在数据洞察中进行数据科学分析的流程一般包括:连接数据科学服务、编写并运行分析代码、导出分析结果。
在数据洞察的左侧边栏中选择“终端”,输入数据科学分析服务地址并选择内核为 “Python 3”即可连接服务。数据洞察支持如下两种方式连接数据科学服务:
数据洞察推荐用户使用SuperMap iServer 10i 数据科学包作为数据科学分析服务。iServer 数据科学服务是面向数据科学家、数据分析师等角色所打造的在线交互式 Python 开发环境,可以在线创建、运行、监控 Python 脚本,基于空间数据进行分布式分析、机器学习等工作。 有关 iServer 数据科学包的安装与启动方法,请查阅 iServer 帮助文档。
数据科学服务通过运行 NoteBook 实现对数据的处理分析,NoteBook 使用 Python 语言进行编写,编写过程中可拖动已添加至数据洞察中的数据作为 NoteBook 的数据源,编写完成后,可点击面板中的“运行”按钮进行分析。也支持用户通过拖动上传 .py 格式文件直接运行。
运行 NoteBook 生成的图片、图表、文本、iFrame 等分析结果可拖动至数据洞察工作台中,整合并制作分析报告。